I found this package pure gold Brick Docs and the creator is someone from the google/ firebase team so I’m confident the technical standar should be great. But the documentation even extended, is hard to follow (at least for me even I’m not new to flutter) and there is not too much info about this besides their doc. Should someone has use it in production?
2 Likes
Firstly welcome to the community!
Secondly, I made a note of this blog post where someone describes using Brick with Supabase as I’m currently considering adopting it for my app
Hopefully this gives you a bit of more of an insight ![]()
It’d be great if someone from the community here has used it and can share their thoughts
Really amazed what big packages are out there that I never have heard about
4 Likes
I tried to use it, but is way too complicated (more complicated than PowerSync).
Brick is intended to be used when you have to deal with RPC or REST.
I prefer to listen to changes in my local database (so, for instance, when a record is changed in my SQLite, any widget that are using that row automatically rebuilds with the new version, so I don’t need to deal with complicated state management, caches, etc.).
Since PowerSync works transparently over SQLite (and it is compatible with Drift), it’s a far superior choice, especially because you can filter your local data easily with SQL (something brick will not allow - it only caches what you already read sometime ago).
Thank you for your reply. Actually that supabase post was the first place where I heard about brick.
I’m considering to migrate a production app (for the moment using firebase and hive but queries are complex, with a lot of duplicated values to keep relation and hive is no longer maintained) so I’m evaluating also moving to supabase and drift.
I probably be using powesync instead of my own implementation (I already did that with hive and is not hard but a lot of work).
Would be cool to see how we both implement the offline-first arch
Thanks, for the reply, will give a try to powersync
Lot of hidden gems in pub.dev. A shame that the search functionality is not really useful…
2 Likes
Hopefully this forum will help make it easier to discover those hidden gems ![]()
1 Like
A blast from my past. Brick was primarily written by an ex-coworker (and friend) of mine at a job I had long before I worked at Google. I was a small contributor because it was being built for our needs at that job.
Looking on Github, the same person continues to maintain it. FWIW, he is infinitely smarter than I am, and I have full confidence that it’s technically sound.
I haven’t had a reason to use it since that job (which I left in 2020), so I can’t speak to it more than that. I feel inspired to dig into it though.
Tried it yesterday, but it didn’t work as expected. The generator only created some file, but not all. @anon92706177 did you use Powerync with Supabase? If yes, how did you set up the sync rules in combination with RLS?
Yes. I use PowerSync, but I use it with Hasura. I find Hasura easier to deal with, especially on row level security, and Supabase doesn’t have functions if you install it on docker, so it is a deal breaker for me.
Since PowerSync is related to POSTGRES, not Supabase/Hasura, it will not know anything about RLS on those plaforms, so, basically, I deal with that twice (one time on Hasura, one time on PowerSync).
It’s kinda hard to do that because PowerSync doesn’t support joins on sync rules (I would love if they could do that, it would be sooooo much easy), so, sometimes, you must be creative.
RLS is the same: sometimes, it is impossible to have a setting for insert (or I could not see how to do it).
For instance, I have a table that holds device information (ID, screen size, OS version, etc.). Then, another table that links devices with users (many-to-many relationship). Then, a table with users. Since devices does not have direct relation with users, I could not get the insert to work (because for me to get to the user_id, I would need to insert users_devices first, but since this is a M-M table, it requires devices to be there first). I could denormalize this M-M association with an array, but that bite me in the SQLite area, so, no RLS for insert for devices table =\
Since sync rules are only for SELECT, they are easier, except that they don’t have support for JOIN, so, again, you can’t get devices directly (so you’ll end up with extra buckets for data that don’t have direct relationship to users):
bucket_definitions:
#global:
#data:
#- SELECT * FROM lists
#- SELECT * FROM todos
user_data:
parameters:
- SELECT token_parameters.user_id as user_id
data:
- SELECT * FROM users_devices WHERE user_id = bucket.user_id
- SELECT * FROM user_settings WHERE user_id = bucket.user_id
- SELECT * FROM users WHERE id = bucket.user_id
device_data:
parameters:
- SELECT device_id FROM users_devices WHERE user_id = token_parameters.user_id
data:
- SELECT * FROM devices WHERE id = bucket.device_id
TD;DR: It’s a bit tricker to sync SELECT RLS with PS SyncRules because one supports relationships, the other doesn’t.
2 Likes
Thanks for this great topic. I’m trying to decide whether I use Brick or Powersync with my Supabase app. I plan to support my app for at least 5-10 years more, so I really need a future proof solution.
Brick is costless. I’m followed supabase’s official video implementing brick + supabase + flutter. At the same time it’s simple, I needed to add at least four pubspec.yaml packages:
brick_offline_first_with_supabase: ^1.0.0
brick_core: ^1.2.1
brick_supabase: ^1.1.0
brick_sqlite: ^3.1.0
I’ve also get three lint messages like this:
The imported package ‘brick_offline_first’ isn’t a dependency of the importing package.
Try adding a dependency for ‘brick_offline_first’ in the ‘pubspec.yaml’ file.
I don’t feel comfortable with these messages.
On the other hand Powersync is an online service, which although provides a free tier, the next tier is $49. Integrations seems a bit trickier because of all the rules needed to be set, which gives me the feeling that I might be doing something wrong.
Can anyone share some more experience?
-
PowerSync can be installed in docker and works very well with Hasura (which, IMO, it’s a far superior solution than Supabase). You can use PowerSync + Hasura in cloud and then, if it is too expensive, go on-premises (but, then again, you’ll need to pay for a server anyway, altough I agree cloud services are thousands of times pricier than hosting yourself on an OVH server)
-
PowerSync has three downsides:
a) They own the primary key (so you can’t make PKs with 2 fields, for instance, the workaround (and, to be clear: workarounds are BAD) is to repeat the multi-column primary key with a concatenated string;
b) There is no JOIN in the sync rules, so getting all the rows that belongs to a user can be very tricky;
c) There is a limit on how many buckets you can create on sync rules (1000). Because of the point b) above, you’ll end up using a lot of those buckets to get what you are looking for (for instance: if you have a many-to-many table that glues together user with something, they’ll have to create a bucket for that m-t-m table and use that to get something. The more complex the database is, the worst PowerSync limitations bite you.
I tried to use Brick, but is far too complicated for something that should be simple, but the most downside is this:
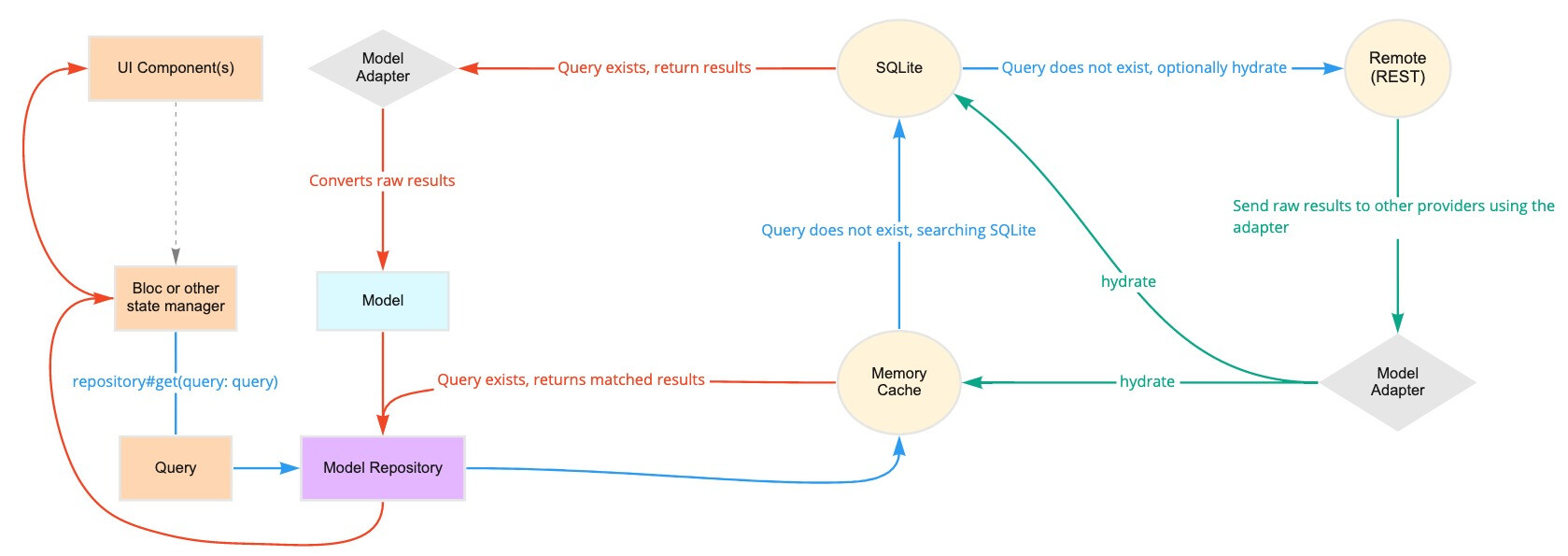
This is NOT offline-first. This is basically a glorified cache (same as PWA). How so? If you get PowerSync, for instance, it will download ALL data that belongs to that user, so it will be ready when the user isn’t connected to the net (you can even trigger a sync and wait for it, to be sure everything is there). Brick, on the other hand, tries to load the data first from the SQLite, then it goes online, then save it locally. But if you are offline, well, no donuts for you - your data is not there, and you can’t fetch it without a connection.
Also, what if your user has multiple devices? What if your data is shared amongst users? How to deal with this using a cache? TL;DR: you don’t. PowerSync will do this scenario nicely. With Brick, you would have to write code to download all the data and manage conflicts (and considering Brick is very complex to set up and use, it is just not worthy)
Other options I tried to use: crdt | Dart package (there’s even a complete To-Do open-source app from the author) and, for 6 years now, I do sync databases manually using a simple lastModifiedDate and isDeleted fields (which only works because this app has only user data, i.e.: the data is not shared, so it is safe to assume multiple devices can sync with last-write-wins and I don’t really need to download data all the time (only on startup is fine enough)).
I’m writing right now a new app that will need all those fancy offline-first-synced-with-other-users stuff, and I’m in the same place as you: evaluating my alternatives. To this moment, I’m inclined towards PowerSync.
3 Likes
Thanks for your answer. You really made me put attention on the side the Brick is not really offline first. Funny thing that I’ve asked this same question to o3-mini-high, grok 3, deepseek, perplexity and qwen. All of them instructed me to choose PowerSync lol.
There’s somw comments on the possibility that Supabase itself will support offline first in the future. Maybe we can use powersync just in the meantime.
If it is on the internet on the AI, it can’t be wrong, right? ![]()
That would be the only thing that would make me change Hasura for Supabase.
Although:
Ah! BTW, forgot to mention that Couchbase has a native Dart package: cbl | Dart package (with Sync support).
I’m just not sure if Couchbase Lite and Sync can be used on-premises or if they are SaaS only
It can: Prepare to Install Sync Gateway | Couchbase Docs
So, another player in the field: Couchbase.
2 Likes
I am currently implementing brick for my flutter app. I am confused in one thing, I want to sync files and I don’t know how I can do it with brick.
Second thing that I want to know is that how we can create a table that we want to keep offline and do not want to sync it?
I am confused in one thing, I want to sync files and I don’t know how I can do it with brick.
Because it can’t. Brick is a database layer only. And it is generally acceptable wisdom that putting files into databases is a bad choice. (I don’t agree with that, but…)
I never used, but PowerSync has this: powersync_attachments_helper | Flutter package
Second thing that I want to know is that how we can create a table that we want to keep offline and do not want to sync it?
I think it is not possible (it is not covered by its policies: Brick Docs). You would have to access the tables directly and not through brick repositories.
Those gotchas are what led me away from Brick.
I learned about Brick from this Appwrite issue.
I haven’t used either much, but just created a new project using appwrite_offline | Flutter package which looks pretty nifty!
Appwrite doesn’t directly support SQL and seems like it’s not really “local-first” either, but these seem pretty appealing to me:
- Open source and self-hosting means you can contribute or migrate if they change pricing
- Dart cloud functions and SDK BUT community is broader than just Dart.
I have written my personal file sync between multiple devices, currently it is in a beta.
If anyone is interested in it then let me know I will share the details.
Since the start of this thread I tried some solutions, including CouchBase, NHost (Hasura + PowerSync) and Supabase (PostgREST + PowerSync).
CouchBase charges per hour, and you have to quote the pricing, so it’s a no-go.
NHost was written by someone who doesn’t have a clue about what he/she/it is writting. It’s unusable.
So far, Supabase + PowerSync is the best option available, but only if you self-host both (because they are so freaking expensive, especially Supabase).
All options out there costs more than I paying my own server on OVH, with plenty of RAM and disk =\
I have written my personal file sync between multiple devices, currently it is in a beta.
If anyone is interested in it then let me know I will share the details.
Please, share. Especially how you resolve conflicts between two people, especially one that changes a record online and one that changes the original record while offline and then try to sync later.